















«Данные и аналитика». Так была обозначена основная тема июньского заседания Комитета АПКИТ по мониторингу развития ИТ-индустрии, в котором приняли участие представители более 25 компаний. Тема, что и говорить, суперактуальная. Имеется немало примеров, как за счет умелого использования имеющихся у них данных (в том числе, о клиентах и/или продажах), компании на десятки процентов увеличивали объемы продаж своих товаров и/или услуг.
Однако не все так просто на магистральном пути развития бизнеса под названием «Оперативная аналитика больших данных». На рис. 1 вы видите слайд, заимствованный из доклада координатора вышеупомянутого Комитета (а также советника по развитию бизнеса на европейских рынках IBM) Натальи Бердыевой. Из него следует, что даже сейчас в среднем по миру доля данных, которые организации так или иначе используют для анализа своей деятельности и принятия правильных решений, очень мала и составляет лишь около 50% для структурированных данных и около 1% для неструктурированных данных. И это притом, что около 80% данных, которые хранят корпорации, являются неструктурированными.
Впрочем, есть и более радикальные оценки. Так например, некоторые аналитики утверждают, что доля неструктурированной информации в современных корпоративных хранилищах составляет не менее 85% от общего объема сохраненных данных. Тут, конечно, возникает вопрос о том, что следует делать: превращать неструктурированные данные в структурированные, а затем обрабатывать полученные массивы хорошо известными аналитическими инструментами; или, используя специальные алгоритмы (в том числе, основанные на методах искусственного интеллекта), оперативно обрабатывать неструктурированные данные и затем результаты этой обработки в реальном масштабе времени предоставлять руководству c использованием новейших программно-аппаратных средств визуализации информации.
Впрочем, идея оперативной обработки больших массивов неструктурированных данных возникла и материализовалась достаточно давно. Ещё в 2013 г. в обзоре CRN «Больше данных — больше денег?» отмечалось: «Большие данные... накапливались и раньше. Другое дело, что их было трудно хранить и анализировать, поскольку это обходилось слишком дорого и/или занимало много времени. Но как только выросла производительность вычислительных систем, емкость систем хранения и снизилась стоимость того и другого, хранение и анализ приобрели экономический смысл, появились... новые архитектурные решения, программные и аппаратные продукты». Однако обратите внимание: неструктурированные (как, впрочем, и структурированные) данные в любом случае надо где-то и как-то хранить! В настоящее время обычно выделяют три основных способа хранения данных:
- традиционные СХД на жестких дисках,
- программно-определяемые СХД на серверах стандартной архитектуры,
- облачное хранение как услуга (cloud storage-as-a-service),
Впрочем, в физических ЦОД’ах, при реализации облачных хранилищ тоже приходится выбирать между традиционными СХД на жестких дисках и программно-определяемыми СХД на серверах стандартной архитектуры. Можно долго рассказывать о том, что такое «программно-конфигурируемое распределенное хранилище данных» и чем оно лучше традиционной системы хранения данных. Однако проще пояснить эти отличия на примере из доклада «Программно-определяемое хранение данных и гиперконвергенция при построении ИТ-инфраструктур», с которым управляющий директор ООО «Росплатформа» Владимир Рубанов выступил на упомянутом выше Заседании.
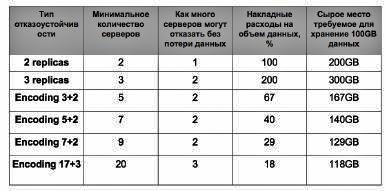
Вполне естественно, что выступление Владимира Рубанова было основано на практике использования двух программных продуктов его компании («Р-Виртуализация» и «Р-Хранилище»), которые в мае этого года были внесены в «Единый реестр отечественного ПО» под регистрационными номерами 3348 и 3380, соответственно. Приведенная на рис. 2 таблица иллюстрирует некоторые технические характеристики одного из этих продуктов.
Смысл данной таблицы вот в чем: если вы строите свой ЦОД на базе программного продукта «Р-Хранилище», который инсталлируется на «голое серверное железо» любых (возможно разных) производителей, то при определении типа отказоустойчивости своего ЦОД’а вправе выбрать любой тип из шести типов, перечисленных в первой колонке данной таблицы.
Предположим, каждый из серверов управляет у вас дисковым массивом емкостью 100 Тб. Тогда при выборе схемы «2 replicas» ваши «накладные расходы» на объемы данных составят 100%, а при выборе схемы «3 replicas» — 200%. Однако это весьма примитивные схемы, сводящиеся, по сути, к двух- и трехкратному дублированию данных. Гораздо интереснее схемы «Encoding 3+2», «Encoding 5+2», «Encoding 7+2» и «Encoding 17+2», обеспечивающие 67, 40, 29 и 18% накладных расходов на объемы данных, соответственно. Чувствуете разницу?
Конечно, расходы на «серверы» и «память» в общих расходах на создание и эксплуатацию ЦОД’а относительно невелики. Как известно (см. например, здесь), у владельцев ЦОД’ов основные расходы составляют затраты на персонал, электроэнергию и прочие «коммунальные расходы». Однако, если речь идет о реализации крупных проектов (например тех, которые обусловлены так называемым «Законом Яровой»), то проценты, перечисленные в четвертой колонке приведенной таблицы, могут вылиться в миллионы, а то и миллиарды рублей.
Разумеется, «Р-Хранилище» — не единственный и далеко не первый в мире продукт, позволяющий строить программно определяемые хранилища данных. Однако поставщики других продуктов такого рода цифры экономии памяти при использовании различных схем хранения данных, увы, не раскрывают.
Источник: Владимир Митин, для crn.ru

