
Ни для кого уже не секрет, что при написании диплома студенты все чаще используют нейросети. За три года доля текста, имеющего машинные шаблоны, в выпускных квалификационных работах выросла в четыре раза! Исследование, которое вызвало широкий резонанс в профессиональном и академическом сообществе, провела компания ReText.AI, проанализировав почти 13 тысяч дипломов за 13 лет. Сегодня авторы этой работы делятся методикой: как отличить текст, написанный человеком, от машинной генерации, почему документы анализировались по абзацам, а не целиком, и где проходит граница между помощью ИИ и подменой самостоятельной работы.
Что показала проверка текста на ИИ
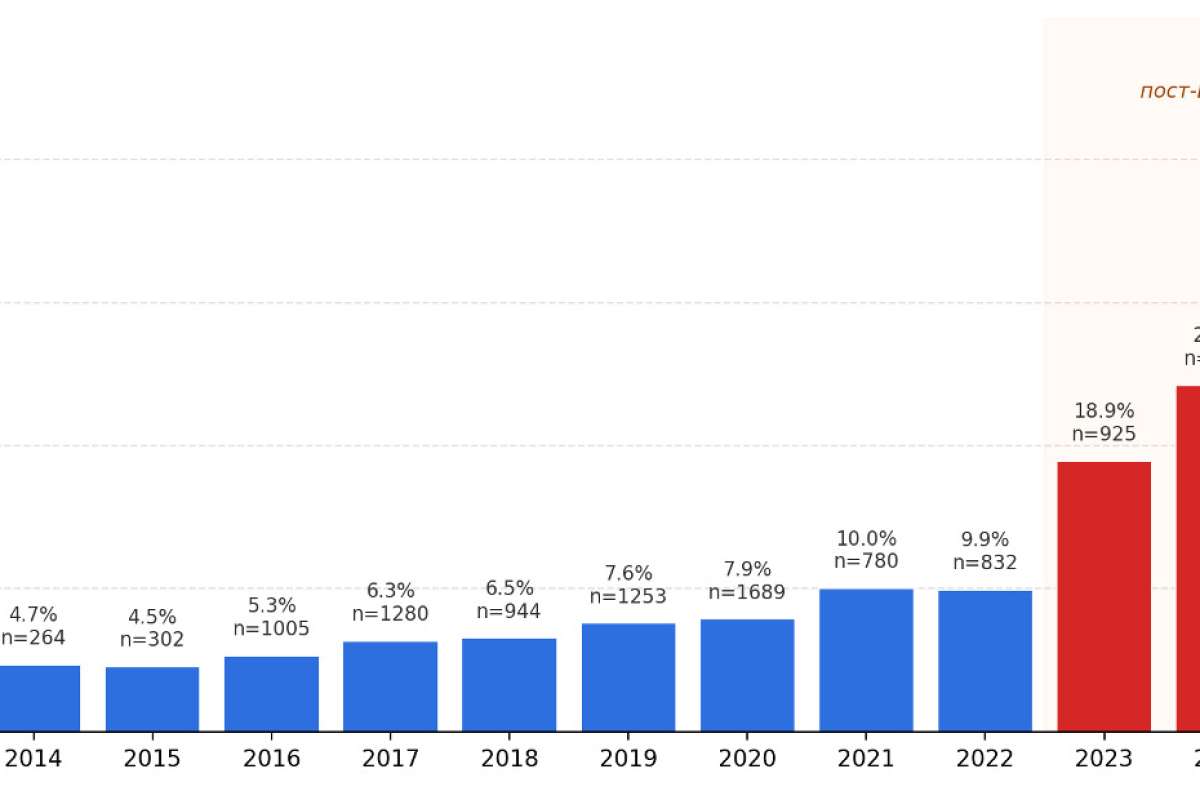
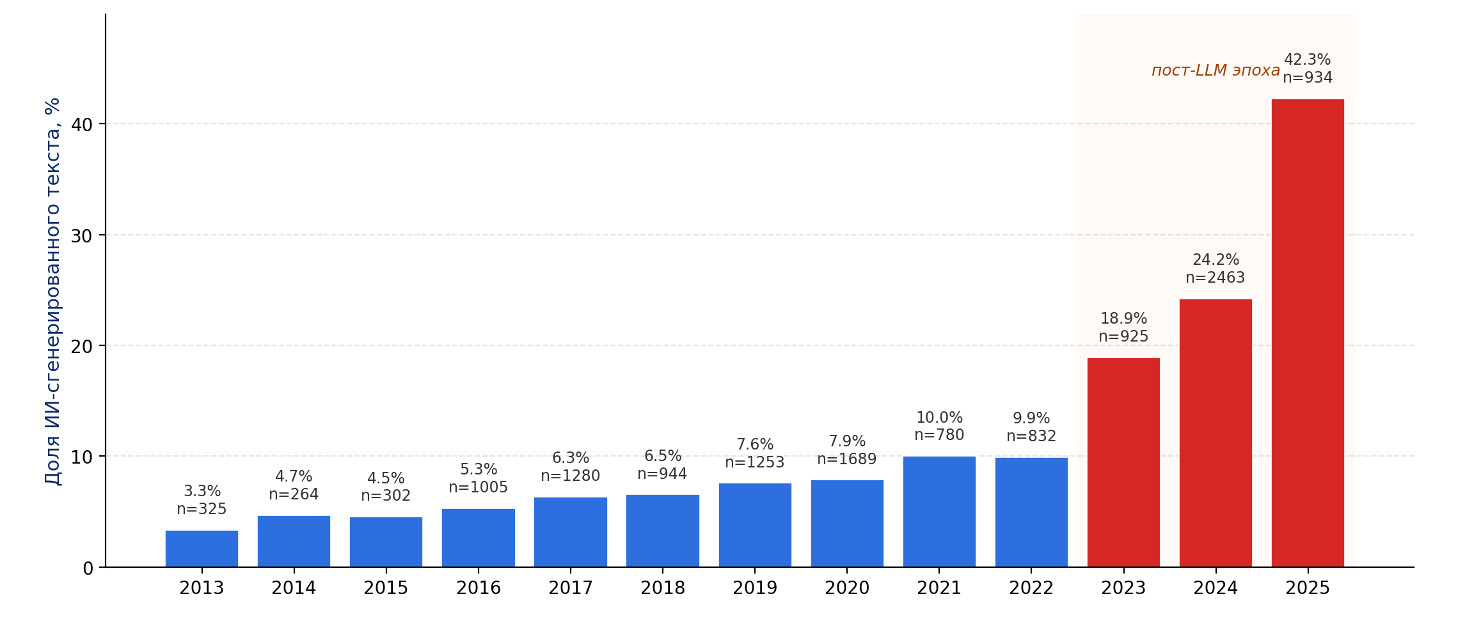
Главный вывод исследования — после 2022 года AI-доля в выпускных работах начала заметно расти. По данным компании:
- AI-доля выросла с 9,9% в 2022 году до 42,3% в 2025 году;
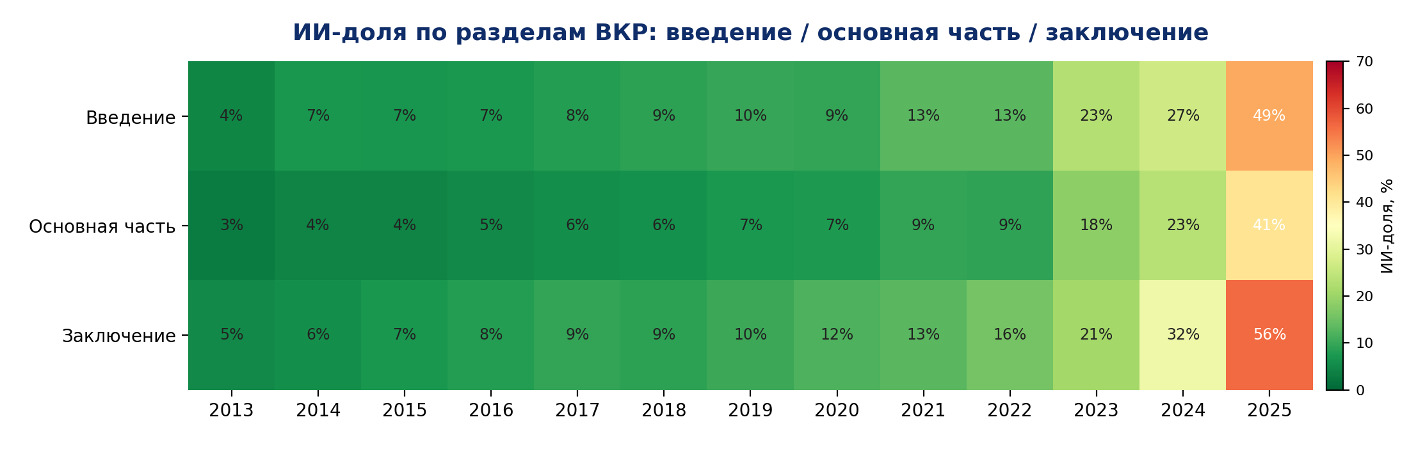
- в 2025 году самые высокие значения чаще встречались в заключении — около 56%;
- во введении AI-доля составила около 49%;
- в основной части показатель был ниже — около 41%;
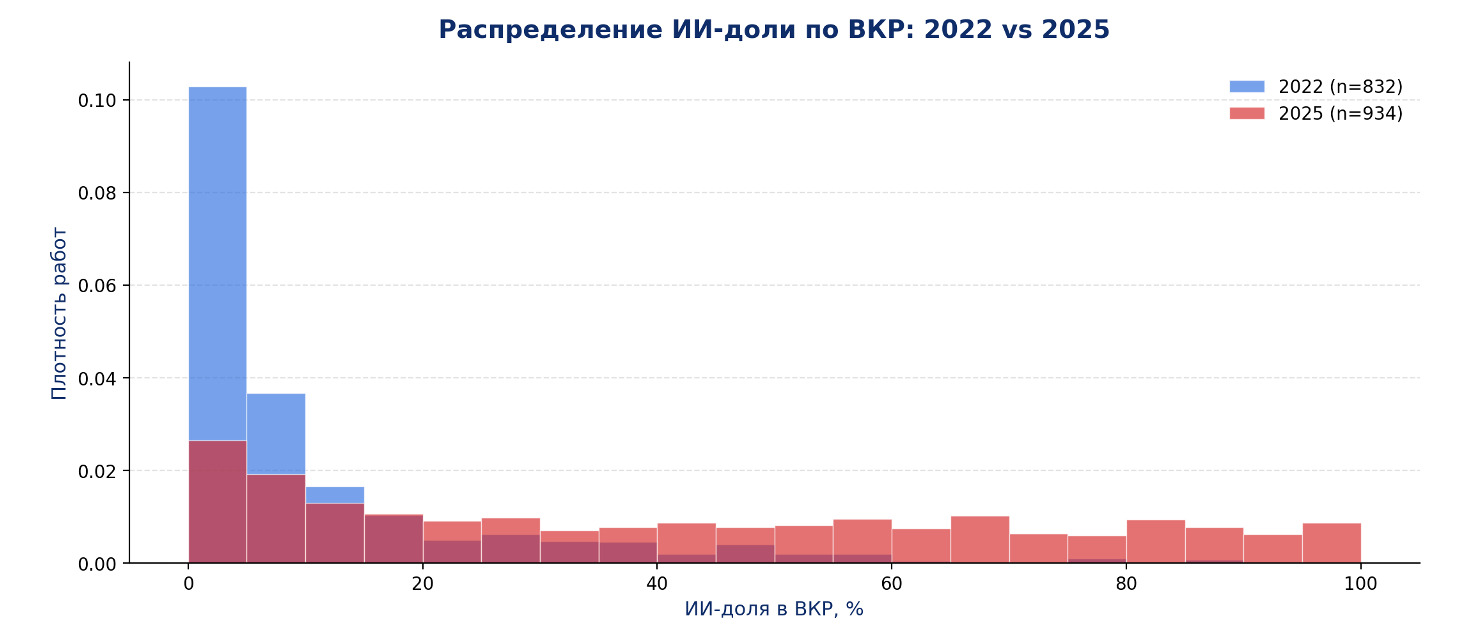
- доля работ, где почти нет признаков ИИ, снизилась: в 2022 году таких работ было около 70%, а в 2025 году — около 23%;
- при сохранении тренда в 2026 году AI-доля может выйти на диапазон
50–60% по корпусу.
Эти цифры показывают общий сдвиг: нейросети стали полноправной частью процесса подготовки, редактуры и структурирования материалов.
«Нас удивил не сам интерес к цифрам, а то, как быстро поменялся разговор. Еще год назад спорили, можно ли вообще использовать ИИ в дипломе. Сейчас и вузы, и студенты, и преподаватели спрашивают другое: как это правильно зафиксировать и где провести границу. Мы изначально делали исследование не для того, чтобы кого-то „поймать“, а чтобы у этой дискуссии появилась опора в данных — и, судя по реакции, такой опоры действительно не хватало», — комментирует основательница ReText.AI Ольга Шкряба.
На чем базируется исследование
В исследовании использовались 12,9 тыс. выпускных квалификационных работ за период с 2013 по 2025 год. После подготовки и фильтрации в анализ вошло 590 млн символов. Для каждой работы рассчитывалась AI-доля — доля текста, которую детектор ИИ классифицировал как похожую на машинную генерацию или
Подготовка текстов к проверке
Перед анализом тексты очищались от фрагментов, которые могли исказить результат. В проверку не включались: титульные листы, аннотации, оглавления, списки литературы, приложения, благодарности, отчеты по практике, подписи к рисункам и таблицам, обрывки формул, служебные и слишком короткие фрагменты. Для анализа брались только абзацы длиной от 500 символов. Короткие фразы часто не дают ИИ-детектору достаточно контекста и могут давать менее устойчивую оценку. Также исключались работы, где после очистки оставалось меньше 10 подходящих абзацев или слишком маленький объем основной части.
Почему анализировали абзацы, а не весь документ
Одна выпускная работа может состоять из очень разных фрагментов. Введение может быть написано шаблонно, основная часть — в более индивидуальной манере, а заключение — снова в стандартном академическом стиле. Если проверять весь документ целиком, эти различия сглаживаются. Поэтому каждый абзац проверялся отдельно. Так можно увидеть не только общий показатель по работе, но и распределение: какие части текста чаще получают метку AI, а какие выглядят более естественно для детектора.
Как работал ИИ-детектор
Для исследования использовался
Как считалась AI-доля
Доля текста, классифицированного как AI, считалась по символам, а не по количеству абзацев. Метод расчета предельно прозрачен: число знаков в фрагментах, которые детектор отнес к ИИ, делят на суммарный объем всех проанализированных абзацев. Например, если после очистки в работе осталось 100 тыс. символов содержательного текста, а 25 тыс. символов пришлись на абзацы, которые детектор отнес к машинному тексту, AI-доля такой работы составляла 25%. Такой подход делает оценку устойчивее: длинные содержательные абзацы сильнее влияют на итоговый показатель, чем короткие фрагменты.
Чем проверка на ИИ отличается от антиплагиата
Антиплагиат обычно ищет совпадения с уже опубликованными источниками: сайтами, статьями, рефератами, базами работ. ИИ-детектор решает другую задачу: он оценивает, насколько текст похож на машинную генерацию или переработку. Поэтому эти проверки нельзя заменять друг другом. Текст может быть оригинальным с точки зрения заимствований, но выглядеть AI-подобным для детектора. И наоборот: текст может быть написан человеком, но содержать совпадения с источниками. В исследовании анализировались именно признаки ИИ-генерации и
Ограничения методологии
У исследования есть несколько важных ограничений. ИИ-детектор не дает абсолютной оценки, он работает с вероятностными признаками генерации текста. Академический стиль сам по себе может повышать вероятность срабатывания, особенно во введениях, заключениях и фрагментах с типовыми формулировками. Детектор может по-разному реагировать на тексты разных языков и на тексты, прошедшие через перевод или редактуру. AI-доля не показывает, какую именно роль играла нейросеть: генерация с нуля, редактура, перевод, перефразирование или помощь с отдельными формулировками. Именно поэтому главная ценность исследования — не в отдельных процентах, а в сравнении периодов и крупных трендов.
Главный вывод
Исследование показало: после выхода нейросетей в широкий доступ в академических текстах заметно выросла доля фрагментов, которые ИИ-детектор классифицирует как похожие на машинную генерацию или переработку.
При этом результаты проверки важно читать аккуратно. Они показывают не «историю создания» конкретного текста, а языковые признаки, которые становятся заметными на большом корпусе. Главный вывод не в том, что нейросети «заменили» авторов, а в том, что они стали частью академического письма. Поэтому дальше важнее не спорить о самом факте использования ИИ, а выстраивать понятные правила: где нейросети допустимы как инструмент редактуры, как фиксировать их использование и как отличать помощь с текстом от подмены самостоятельной работы.
Источник: Пресс-служба компании ReText.AI